
This time I will explain why Excel-based business process are much more expensive than the Database-based ones (see part 1 of the article).
Hidden chaos and waste of money
I tried to capture in a picture the travel of data where an Excel spreadsheet is used to communicate between the different business actors which are involved in the decision and physical application of the new data:
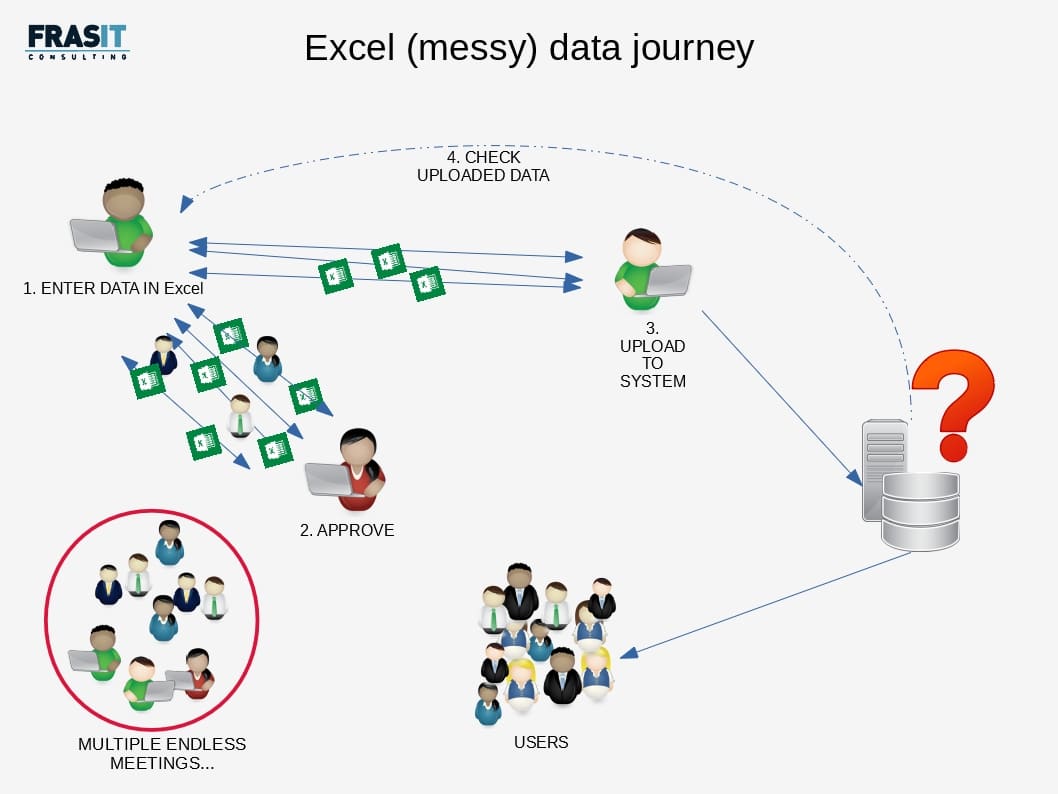
In my graphic I have actually been too generous: the reality is many times worst than the picture! And the time/money waste is unbelievable.
Step 1
This is actually the most critical phase as the person that needs a data change is not always the person that owns the data. In your career you have been probably received and sent data for you were not responsible for.
In big organizations it happens quite often for a number of reasons, among them:
- The need of a department crosses the responsibilities of another department. Basically: Dept. A need this change now but Dept. B owns or need to approve the data
- A department need the data change, but currently nobody owns the data, and nobody feels comfortable enough (or dare) to take ownership of the changed data, because the old data where generated long time ago by <who knows…>
- Dept. A need a change but it knows that the change will affect other departments, therefore they get stuck in the dilemma and the change is postponed until somebody will claim ownership of the data, or another department dares to make the change.
Step 2
The approval of the change is another time consuming task, because all the reasons listed in Step 1, but also because without clear ownership of the data, there is no clarity about who should approve the data.
And when it is clear who are the approvers then it require a lot of negotiation and cross checks with other entities to coordinate the change request, and not always the approvers feel the urgency of the request, so the meetings are cancelled, postponed or ignored.
Again, the approval of the change get delayed until somebody dare to push forward the process (which might not be the right approver/s. Many times developers just do it, crossing fingers and hoping that nobody blame them in the future).
Step 3
Finally, after months of negotiation and endless meetings, the data land on the desk of the person that will physically implement the change uploading the data in the system: the developer or system administrator. What can go wrong? Actually a lot!
- As seen in Step 2, the developers implement the change without actual approvers. They have very good knowledge of the system, so they feel comfortable enough to just make the change. If something goes wrong, then it starts the blame game…
- The approved changes are not the ones required by the department: during the passage from Dept. A to the approvers and from the approvers to the developer, the data change (anyone seen strange letters in a spreadsheet due to the different character encoding? Or a removed space that didn’t look right, but actually it affects the target system?)
- The data cannot be implemented as proposed and approved because it will break some business rule in the system, or because it cannot be physically uploaded due technical constraints.
The result: we needed “THIS”, but after few months of fights and discussions we got “THAT”. Or worst: we needed “THIS”, but after months of fights and discussions we got “Nothing”.
Step 4
For the first time, the data are live in the system, seen by requester and approvers as they will be used in reality. Of course, if something is wrong, then you restart the whole process from Step 1. Extra months of delay, extra money gone…
You can do it better
Performing all the steps in the system where the data belong we can achieve maximum control over the data and enforce correctness of the changes.


Now the time to implement data changes can be measured in hours instead of weeks or months. But how did I transformed slide 1 in slide 2 with apparently no effort? There is a trick:
You need to identify in advance the data owner and approvers. But this time you do it only once, instead to repeat the process every time a single change is needed!
If you put the data where they belong (the database), you have encoded forever in the system the data owner, the approvers and the right data. There is no more doubt about “who” should do “what”, “how” and “when” the change happened.
I hope that next time you open an Excel spreadsheet, an alarm bell rings also in your mind 😉
Feel free to comment telling me your “data horror” story, it would be interesting to understand if in your company the spreadsheet pattern is also blindly followed.
Still in doubt?
Read this is article from The Wall Street Journal explaining why you need to keep your data in the system, not in spreadsheets.
